
|
Sam Eldin Artificial Intelligence
Fundamentals© |
|---|
|
Artificial Intelligence Fundamentals Introduction: Artificial Intelligence (AI) is the hottest subject and learning or mastering AI as an Information Technology (IT) architect-analyst will require lots of energy and time. Being IT professional may be a bonus and the learning curve is consideringly big if not Hugh. The following are quick questions that we will try to answer with short answer and present images which may help put a picture to what are presenting. What is AI? What AI is based on? What is AI structure or major components? What are AI’s nuts and bolts? What is AI? In a nutshell, AI is the ability of a computers system to mimic human intelligence. What AI is based on? AI uses computer science, data analytics and statistics, hardware and software engineering, linguistics, neuroscience, and even philosophy and psychology. What is AI Structure or major components? 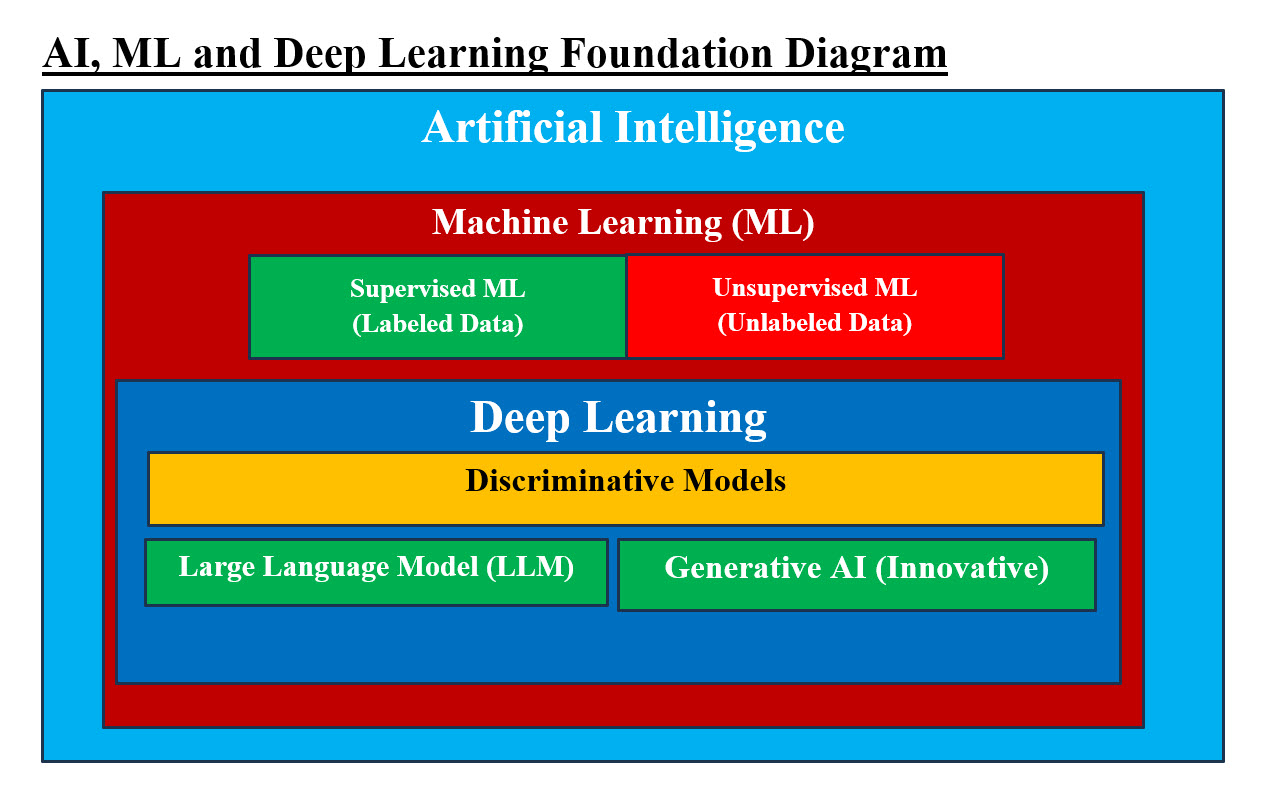
Image #1 - AI, ML and Deep Learning Foundation AI major components are: 1. AI 2. ML 3. Deep Learning 4. Discriminative Model 5. Large Language Model (LLM) 6. Generative AI Image #1 presents a rough image of AI Foundation. What are AI’s nuts and bolts? The amount and the size of details for AI analysis, architect and design is not small nor simple, we are presenting more of crash course with examples and images for our audience to grasp the concepts and system flow as fast as possible. The following are first components: 1. Data points 2. Label Data 3. Unlabeled Data 4. Token 5. Weight 6. Relationship between Label of data points 7. Machine Learning (Supervised and Unsupervised) 8. Deep Learning 9. Discriminative Models 10. Text Data 11. Large Language Model 12. Generative AI 13. Generative AI Model Types 14. Text, Voice and Sound 15. AI patterns 16. Multilayer perceptions 17. Convolution Neural Networks 18. Transformers 19. Backpropagation 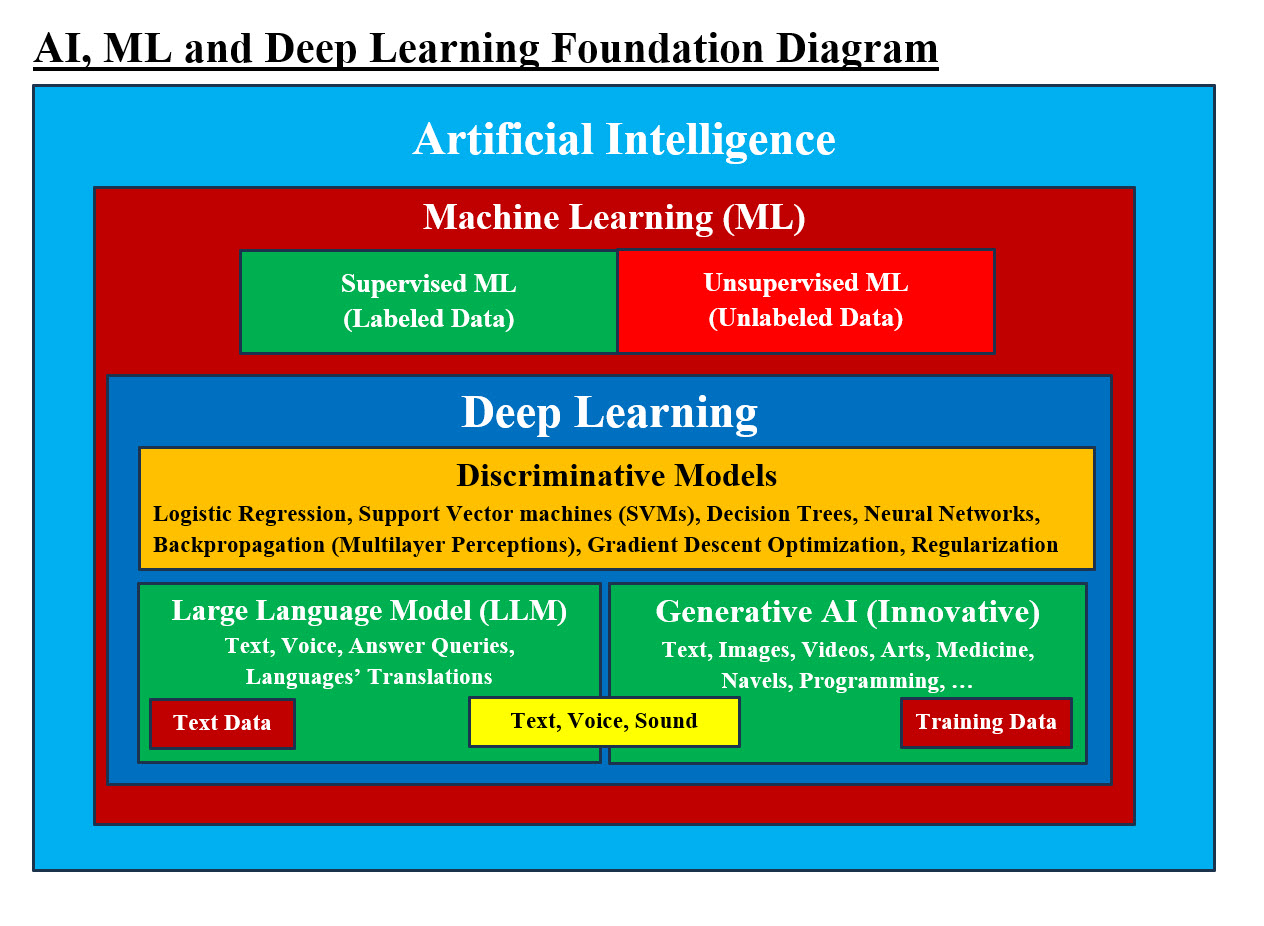
Image #2 - AI, ML and Deep Learning Foundation Image #2 is a rough presentation of AI’s nuts and bolts. We would be present all the components with image plus extra points or subject related to these components. Data Points: Data can be anything such pixels within a graph, a Java object, a business unit, anything which presents a value in specific goal of research or a project. The term data point is roughly equivalent to datum, the singular form of data within a dataset. A data point is a single piece of information or observation that represents a specific value or characteristic within a larger dataset. It can be a numerical value, text, an object (Java Object) or even an image. Data Point should be unique and can be measured and compared. Examples of data points: • Amount of money spent each day • Length of time it takes to finish a task • Number of users on a web server at a particular time of day • Number of clients who visit a company's website • Number of likes on a social media post • Number of hours of slept each night Label Data: Label is also known as Tag, Ticket, Sticker, Marker or any name which identifies the data. Why labeling data is important? When it comes to Machine Learning (ML), the data used in ML analysis and processing must be: 1. Model accuracy 2. High-quality labeled 3. Can be implemented in ML Training Data How Labeled data is created? Labeled data is created through a process called "data labeling," where raw data (like images, text, or audio) is manually or automatically assigned descriptive labels or tags by human annotators or specialized algorithms, providing context and meaning for machine learning models to learn from; essentially, it involves attaching specific categories or classifications to data points based on predefined guidelines. Unlabeled Data: Unlabeled data refers to data elements that lack distinct identifiers or classifications. These pieces of data don't come with "tags" or "labels" that indicate their characteristics or qualities, making their interpretation a more challenging task. Examples of unlabeled data: • A list of emails without spam or not spam tags • A collection of images without identifiers like "people", "cars", or "animals" • A list of numbers • A collection of objects without any associated metadata • Social media posts • Medical scans • News articles Uses of unlabeled data: • Unsupervised learning: A type of machine learning that uses unlabeled data to discover patterns and insights without human supervision • Exploratory data analysis: A technique that uses unlabeled data to explore data • Plan recognition: A technique that uses unlabeled data to recognize plans Token: A token is an instance of a sequence of characters in some particular document that are grouped together as a useful semantic unit for processing. A token is a collection of characters that has semantic meaning for a model. A token works as a replacement for the original data Tokenization: Data tokenization is a robust process designed to protect sensitive information while maintaining its utility for a wide variety of business operations. By substituting sensitive data elements with unique tokens, organizations can ensure a high level of data security – without sacrificing functionality. Tokenization is the process of converting the words in your prompt into tokens. Weight: In analysis, "weight" refers to a numerical value that determines the strength of data, token, processes. What is the function of weight in AI? Weights in AI refer to the numerical values that determine the strength and direction of connections between neurons in artificial neural networks. These weights are akin to synapses in biological neural networks and play a crucial role in the network's ability to learn and make predictions. Relationship between Label of data points: In machine learning, a "label" of a data point refers to the assigned category or value that describes the data point For example, you may have 10 images of 10 different dogs and 10 image of different cats. ML would be using these images or label data points to identify a new image as a dog, cat or others. Therefore, the quality of the label data points would help ML perform a better job in identifying a dog or a cat. Sam Eldin Approach to ML: Our ML approach is based on giving Zero and Ones of a dog, where ML would use these Zeros and Ones to create patterns and number of patterns can be in the millions as the computer processing allows our pattern building. These patterns would be scaled to create a number (millions) of possible scaled patterns. The creating and selection of best patterns based a weight scale would give us the best possible choice of what a dog would look like. Our approach is more intelligent, faster, scalable, dynamic, not labor intensive, and can improve with our ML learns more on how to improve its scaling, performance and testing Machine Learning (Supervised and Unsupervised): Supervised machine learning (ML) is a machine learning technique that uses labeled data to train algorithms to predict outcomes. The goal is to create a model that can accurately predict outputs for new data. How it works: 1. Training: The model is trained using labeled data, which includes input objects and desired output values 2. Learning: The model learns the relationship between the input and output data 3. Prediction: The model uses the learned relationship to predict the output for new data Unsupervised machine learning is the process of inferring underlying hidden patterns from historical data. Within such an approach, a machine learning model tries to find any similarities, differences, patterns, and structure in data by itself. No prior human intervention is needed. Sam Eldin Thinking: Again, in Unsupervised machine learning, algorithms must be provided and that is opening a can of worms to bias and getting lost. To us Unsupervised machine learning is more pattern search and guessing game. Convolution Neural Networks: Using filter (2d array of values) which scan the entire image looking possible match and give it a value-weight for performing optimization. Example, using an array of 4X4 pixels to find its matching pattern or copy in a file of pixels (image file). Convolution is a mathematical operation that combines two sets of information to create a third function. In a convolutional neural network (CNN), convolution is a process that filters input data to extract features. IBM definition of A neural network: A neural network is a machine learning program, or model, that makes decisions in a manner similar to the human brain, by using processes that mimic the way biological neurons work together to identify phenomena, weigh options and arrive at conclusions. Every neural network consists of layers of nodes, or artificial neurons—an input layer, one or more hidden layers, and an output layer. Each node connects to others, and has its own associated weight and threshold. If the output of any individual node is above the specified threshold value, that node is activated, sending data to the next layer of the network. Otherwise, no data is passed along to the next layer of the network. Neural networks rely on training data to learn and improve their accuracy over time. Once they are fine-tuned for accuracy, they are powerful tools in computer science and artificial intelligence, allowing us to classify and cluster data at a high velocity. Tasks in speech recognition or image recognition can take minutes versus hours when compared to the manual identification by human experts. One of the best-known examples of a neural network is Google’s search algorithm. As it turns out, there are many different neural network architectures, each with its own set of benefits. The architecture is defined by the type of layers we implement and how layers are connected together. The neural network above is known as a feed-forward network (also known as a multilayer perceptron) where we simply have a series of fully-connected layers. Today, I'll be talking about convolutional neural networks which are used heavily in image recognition applications of machine learning. Convolutional neural networks provide an advantage over feed-forward networks because they are capable of considering locality of features. Sam Eldin View of Neural network: In a nutshell Neural network is filtering input data based a given algorithm. When a neural network "filters input based on a given algorithm," it essentially means the network has been designed and trained to process data by applying the principles of a specific algorithm, effectively selecting and prioritizing certain aspects of the input while discarding others, similar to how a traditional filter would work, but with the added flexibility of learning complex patterns from data through its neural network architecture. Our ML Value-Weight Matrices: Our ML creates matrices of Value-Weight where our ML would be selecting items based their highest Value-Weight number. Plus, our cross-referencing of such value would be used to check for errors, duplicates and other factors to make an educated guess of possible answer. Perceptron: A Perceptron is an algorithm for supervised learning of binary classifiers. This algorithm enables neurons to learn and processes elements in the training set one at a time. Feed-Forward Network (also known as a multilayer perceptron): Multilayer Perceptron: What is the principle of multilayer perceptron? The core principle behind the functioning of a multilayer perceptron lies in backpropagation, a key algorithm used to train the network. During backpropagation, the network adjusts its weights and biases by propagating the error backwards from the output layer to the input layer. A Multilayer Perceptron (MLP) can be used to identify characteristics within data by learning complex non-linear relationships between input features and target variables, allowing it to pinpoint which specific aspects of the data are most important for making accurate predictions or classifications, essentially highlighting the key characteristics that differentiate different categories within the data set. MLPs are significant in machine learning because they can learn nonlinear relationships in data, making them powerful models for tasks such as classification, regression, and pattern recognition. Sam Eldin Views: Our Cross-referencing data matrices would produce a far more intelligent educated guess than all Deep Learning multilayer perceptron processes. Example: The following example is more presentation of how to use Value-Weight to predict action of a person or an entire city or metropolitans. Credit risk assessment: A bank loan officer can use an Multilayer Perceptron (MLP) to identify characteristics of customers who are likely to default on loans. The officer can train the MLP using a sample of past customers, then use it to classify new customers. Sam Eldin Matrices and Cross-Referencing of Matrices: Let us look at the following use case scenario. A person named XX with monthly Income of $4,000 and monthly expenses of $3,440. XX’s history payment record can be used answer a number of questions and possible results. The following table is present three years of payment history. P = Paid N = Not paid
From the data we can conclude the following: Possible drug addiction is 100% – can we sell person XX drugs and alcohol – what is the chance of buying our drugs Medication needed is 90% – can be sell person XX medications Phone addiction – Phone is critical - not willing to loss the phone Scenario #1: If person XX has only $1,200 then what will XX pay first? We can use these matrices for 10 million persons with XX income and we can learn and use such data in many ways legal or not. Cross-reference of matrices would be that out of 10 million in a City Named GGV, resident are will to skip payment on Gas and heat bills and alcohol consume-possible addiction is quite high. Deep Learning: Deep learning is a type of machine learning that uses artificial neural networks to learn from data. Artificial neural networks are inspired by the human brain, and they can be used to solve a wide variety of problems, including image recognition, natural language processing, and speech recognition. Discriminative Models: Discriminative models, in the realm of machine learning, are: 1. Algorithms designed to directly model 2. Learn the boundary between different classes or categories in a dataset Most of the Machine Learning and Deep Learning problems that you solve are conceptualized from the Generative and Discriminative Models. In Machine Learning, one can clearly distinguish between the two modelling types: • Classifying an image as a dog or a cat falls under Discriminative Modelling • Producing a realistic dog or a cat image is a Generative Modelling problem The more the neural networks got adopted, the more the generative and discriminative domains grew. To understand the algorithms based on these models, you need to study the theory and all the modelling concepts. Text Data: Textual data is information that is stored and written in a text format. It can be anything from emails to blog posts to social media posts and online forum comments. In short, it's any data that has been expressed in words. Large Language Model (LLM): A large language model (LLM) is a type of artificial intelligence (AI) that can understand, process, and generate human language. LLMs are trained on massive amounts of data, which allows them to perform natural language processing (NLP) tasks. A large language model (LLM) is an artificial intelligence (AI) system that can understand and produce human-like text. LLMs are trained on massive amounts of data, using machine learning techniques. Examples of LLMs: tGPT, Claude, Microsoft Copilot, Gemini, and Meta AI How does LLMs work? LLMs are a type of deep learning, a subset of machine learning. Base on the the data they've been trained on, LLMs would respond to user requests with relevant content by analyzing patterns. LLMs can perform a variety of tasks, including: • Translating languages • Answering questions • Summarizing text LLM limitations (Hallucinations): LLMs can produce false or inaccurate outputs, known as hallucinations. This happens because LLMs predict the next word or phrase, but they can't fully understand human meaning. LLM applications: LLMs can be used in many industries, including content summarization, writing, and translation. Generative AI: Generative AI, or gen AI, is a type of artificial intelligence (AI) that creates new content based on user prompts. It can generate text, images, videos, audio, and more. How does it work? • Generative AI uses machine learning models to understand and mimic the structure of input data • It can learn complex subjects like programming languages, chemistry, and biology • It can reuse what its knowledge base to solve new problems Generative AI Model: Generative AI is the kind of AI you can be used to create: • New text • Visual content • Audio content It's not a new concept, but it's been newly simplified and made accessible to the average user. Now, anyone can use generative AI to massively speed up content creation tasks. Generative AI Model Types: Generative Adversarial Networks (GANs): There are many types of generative AI models, including generative adversarial networks (GANs), variational autoencoders (VAEs), transformer models, autoregressive models, flow models, and Stable Diffusion. A generative adversarial network (GAN) has two parts: • The generator learns to generate plausible data. The generated instances become negative training examples for the discriminator. • The discriminator learns to distinguish the generator's fake data from real data The discriminator penalizes the generator for producing implausible results. When training begins, the generator produces obviously fake data, and the discriminator quickly learns to tell that it's fake: Generative Adversarial Networks (GANs): • Two neural networks compete to create authentic data • The generator creates output, and the discriminator evaluates its authenticity Variational Autoencoders (VAEs): • Encode input data, optimize it, and store it in a latent space • When prompted, the data is reconstructed from the latent space Transformer Models: • Have multiple layers that use a self-attention mechanism and feed-forward network • Identify and memorize patterns in data Autoregressive Models: • Generate sequences of data, like text, music, or time series data • Generate data one element at a time, considering the context of previously generated elements Flow Models: • Flow models Learn input and output distributions transformations and Generate high-quality images and data. Stable Diffusion: • An open-source tool that allows users to train their own models to generate images from text descriptions GPT-3: • A transformer model that excels in generating coherent and contextually relevant textual content AI patterns: The seven patterns of AI are: 1. Hyper-personalization 2. autonomous systems 3. predictive analytics and decision support 4. conversational/human interactions 5. patterns and anomalies 6. Recognition systems 7. Goal-driven systems. Personalization: Personalization is the act of tailoring a service or a product to accommodate a specific individual or group. As the name suggests, personalization is centered on the person, fulfilling a particular customer's needs and reflecting them in the product or service. Hyper-personalization: It's also known as one-to-one marketing. Hyper-personalization is a marketing strategy that uses artificial intelligence (AI) and real-time data to create content, products, and services that are tailored to each customer. Autonomous Systems: An autonomous system is a system that can operate independently and make decisions without human intervention. Autonomous systems use intelligence to sense, process, and learn from their environment. They can adapt their behavior to unexpected events and make decisions based on real-time data. Predictive Analytics and Decision Support: Predictive Analytics and Decision Support refers to a system that uses statistical modeling, machine learning, and data mining techniques to analyze historical data and predict future trends, thereby providing insights that guide informed decision-making within an organization, helping to mitigate risks, improve efficiency, and identify potential opportunities. Predictive analytics and decision support are used in many industries to make better decisions. Here are some common applications: • Sales forecasting: Predicting how much a company will sell in the future. This involves analyzing historical sales data, market trends, and other factors. • Customer churn prediction: Predicting which customers are likely to stop using a product or service. This involves analyzing customer data, such as purchase history and interactions with customer service. • Fraud detection: Identifying and preventing fraudulent activities, such as money laundering or theft of data or resources. This involves monitoring transactions, applications, and user behavior. • Risk assessment: Identifying potential hazards and analyzing what could happen if they occur. This helps businesses and government agencies understand the potential risks they might face. • Clinical decision support: Providing clinicians, staff, and patients with timely information to help inform decisions about a patient's care. This can help improve patient outcomes and lead to higher-quality health care. • Predicting customer preferences: Using predictive analytics to predict what products or services customers are likely to want. • Forecasting demand: Using predictive analytics to forecast demand for products or services. • Preventing equipment breakdowns: Using predictive analytics to prevent equipment breakdowns in manufacturing. • Predicting player performance: Using predictive analytics to predict player performance in sports. Conversational/Human Interactions: Conversational interaction defined in the broad sense of all face-to-face or technology-mediated forms of interaction that use language encompasses a wide range of different types of talk. Patterns and Anomalies: Patterns are recurring or significant patterns in data sets. Anomalies are data points that deviate from the expected norm. Recognition systems: Recognition of human individuals, or biometrics, used as a form of identification and access control. Facial recognition system, a system to identify individuals by their facial characteristics. Fingerprint recognition, automated method of verifying a match between two human fingerprints. Recognition systems, such as facial recognition, are used for access control and identification by comparing a person's unique physical characteristics to a database of authorized users. If a match is found, the system grants access to the person. Goal-driven systems: Recognition systems are technologies that identify people or objects based on their characteristics. They are used for access control and identification. Multilayer perceptions: The core principle behind the functioning of a multilayer perceptron lies in backpropagation, a key algorithm used to train the network. During backpropagation, the network adjusts its weights and biases by propagating the error backwards from the output layer to the input layer. hidden layers: In neural network terminology, additional layers between the input layer and the output layer are called hidden layers, and the nodes in these layers are called neurons. Backpropagation: Backpropagation is a machine learning technique essential to the optimization of artificial neural networks. It facilitates the use of gradient descent algorithms to update network weights, which is how the deep learning models driving modern artificial intelligence (AI) "learn." Backpropagation allows us to readjust our weights to reduce output error. The error is propagated backward during backpropagation from the output to the input layer. This error is then used to calculate the gradient of the cost function with respect to each weight. Transformers: Transformers are neural networks that learn to change input sequences into output sequences. They're a key part of deep learning and are used in natural language processing (NLP), computer vision, and more. Transformer take a broken sentence turn it into meaningful token, then transform it make into a sentence which makes sense and can be used in other sentences or expressions. |
|---|